
Scikit-learn is a machine learning library in Python that provides a range of algorithms for classification, regression, clustering, dimensionality reduction, and model selection. It is designed to be user-friendly, efficient, and easy to integrate with other Python libraries. scikit-learn is built on the popular NumPy and SciPy libraries, which provide functionality for array computation and scientific computing, respectively. This makes scikit-learn a great choice for data scientists and machine learning practitioners who need to perform fast and reliable data analysis tasks.
One of the key advantages of scikit-learn is its simplicity and ease of use. The library is designed to have a consistent interface, with each algorithm having a similar implementation pattern. This makes it easy for users to switch between different algorithms and use them interchangeably in their work. In addition, scikit-learn provides many useful functions for preprocessing and evaluating the performance of machine learning models, including functions for splitting data into training and testing sets, computing accuracy scores, and generating confusion matrices.
Another great feature of scikit-learn is its wide range of algorithms for various machine learning tasks. Whether you are working on a classification problem, a regression task, or need to perform clustering or dimensionality reduction, scikit-learn has a suitable algorithm that you can use. The library is also highly modular, allowing you to use only the algorithms and functions that you need for your specific task. This makes it a great choice for both researchers and practitioners, who can easily experiment with different algorithms and choose the best one for their problem.
In this article and tutorial, we will cover the basics of scikit-learn and provide code examples to help you get started.
Getting Started with scikit-learn
The first step in using scikit-learn is to install it. The easiest way to do this is using the pip package manager:
pip install -U scikit-learnRegression
Here’s a simple example of how you can use scikit-learn for regression. In this example, we’ll use a dataset of housing prices and try to predict the median value of owner-occupied homes.
First, let’s start by importing the necessary libraries and loading the data:
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
df = pd.DataFrame(boston.data, columns=boston.feature_names)
df['MEDV'] = boston.targetNext, let’s split the data into training and testing sets, so we can evaluate the performance of our model:
from sklearn.model_selection import train_test_split
X = df.drop('MEDV', axis=1)
y = df['MEDV']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)Now, let’s fit a linear regression model to the training data:
from sklearn.linear_model import LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)Finally, let’s use our model to make predictions on the test data and evaluate its performance:
y_pred = reg.predict(X_test)
from sklearn.metrics import mean_squared_error
mse = mean_squared_error(y_test, y_pred)
print("Mean Squared Error:", mse)This is just a simple example of how you can use scikit-learn for regression, but there are many other regression algorithms available in the library that you can try. Additionally, scikit-learn provides many useful functions for model evaluation and hyperparameter tuning, allowing you to fine-tune your models and get the best possible results.
Classification
Classification is a supervised machine learning task that involves assigning a class label to a given input data.Here’s an example of how you can use scikit-learn for classification. In this example, we’ll use the iris dataset and try to classify the species of iris based on their sepal and petal length and width.
First, let’s start by importing the necessary libraries and loading the data:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['species'] = iris.target
df['species'] = df['species'].map({0: iris.target_names[0], 1: iris.target_names[1], 2: iris.target_names[2]})Next, let’s split the data into training and testing sets, so we can evaluate the performance of our model:
from sklearn.model_selection import train_test_split
X = df.drop('species', axis=1)
y = df['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)Now, let’s fit a decision tree classifier to the training data:
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)Finally, let’s use our model to make predictions on the test data and evaluate its performance:
y_pred = clf.predict(X_test)
from sklearn.metrics import accuracy_score
acc = accuracy_score(y_test, y_pred)
print("Accuracy:", acc)This is just a simple example of how you can use scikit-learn for classification, but there are many other classification algorithms available in the library that you can try. Additionally, scikit-learn provides many useful functions for model evaluation and hyperparameter tuning, allowing you to fine-tune your models and get the best possible results.
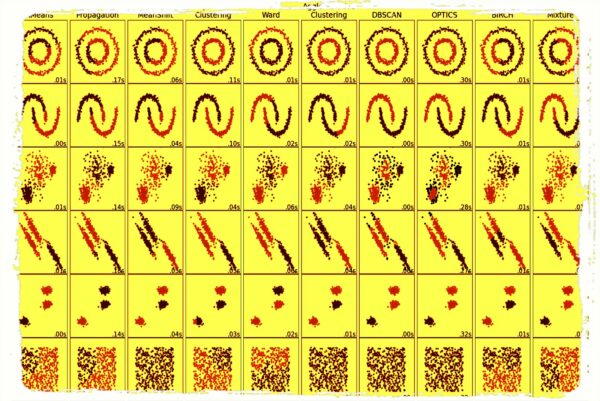
Clustering
Clustering is an unsupervised machine learning task that involves grouping similar data points together. Here’s an example of how you can use scikit-learn for clustering. In this example, we’ll use the iris dataset and try to cluster the samples into different groups based on their sepal and petal length and width.
First, let’s start by importing the necessary libraries and loading the data:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)Now, let’s fit a KMeans clustering model to the data:
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3)
kmeans.fit(df)Finally, let’s use our model to predict the cluster labels for each sample:
y_kmeans = kmeans.predict(df)
This is just a simple example of how you can use scikit-learn for clustering, but there are many other clustering algorithms available in the library that you can try. Additionally, scikit-learn provides many useful functions for evaluating the performance of clustering algorithms and determining the optimal number of clusters.
Dimensionality Reduction
Dimensionality reduction is a technique for reducing the number of dimensions in a dataset. This can be useful for visualizing high-dimensional data and for reducing the computational complexity of machine learning algorithms.Here’s an example of how you can use scikit-learn for dimensionality reduction. In this example, we’ll use the iris dataset and try to reduce the number of features while preserving the information in the data as much as possible.
First, let’s start by importing the necessary libraries and loading the data:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
Now, let’s fit a Principal Component Analysis (PCA) model to the data:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(df)Finally, let’s use our model to transform the data into a lower-dimensional space:
df_reduced = pca.transform(df)This is just a simple example of how you can use scikit-learn for dimensionality reduction, but there are many other dimensionality reduction algorithms available in the library that you can try. Additionally, scikit-learn provides many useful functions for visualizing the results of dimensionality reduction and evaluating the performance of the algorithms.
Model Selection
Model selection is the process of choosing the best machine learning model for a given task.
Here’s an example of how you can use scikit-learn for model selection. In this example, we’ll use the iris dataset and try to build a classification model to predict the species of iris based on their sepal and petal length and width.
First, let’s start by importing the necessary libraries and loading the data:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
X = df
y = iris.targetNow, let’s use cross-validation to evaluate the performance of several different classification algorithms:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
models = [
LogisticRegression(),
DecisionTreeClassifier(),
SVC(),
KNeighborsClassifier()
]
for model in models:
scores = cross_val_score(model, X, y, cv=5)
print("Accuracy: %0.2f (+/- %0.2f) [%s]" % (scores.mean(), scores.std(), model.__class__.__name__))In this example, cross_val_score is used to evaluate the performance of each model using 5-fold cross-validation. The mean accuracy and standard deviation of the accuracy for each model are then printed.
Based on the results, we can choose the model with the highest mean accuracy and lowest standard deviation as our final model. In this example, it would be the LogisticRegression model, but your results may vary.
This is just a simple example of how you can use scikit-learn for model selection, but there are many other evaluation metrics available in the library that you can try. Additionally, scikit-learn provides many useful functions for tuning the hyperparameters of the models and improving their performance.
Youtube / Video Tutorials
There are several YouTube videos that cover various aspects of Scikit-Learn, a popular Python library for machine learning. Here are some resources you might find helpful:
- Scikit-Learn Tutorial Series: This is a series of 28 videos by Sentdex that covers the basics of Scikit-Learn, including data preprocessing, model selection, and evaluation. The videos are easy to follow and provide plenty of hands-on examples.
- “Scikit-Learn Tutorial by Simplilearn”: In this video, the presenter provides a comprehensive overview of scikit-learn, including its key features, how to install it, and how to use it for machine learning tasks such as classification, regression, clustering, and dimensionality reduction.
- “Learning Scikit-Learn” by Google Cloud Tech: In this tutorial, the presenter provides an introduction to scikit-learn, including its key features and how to install it.
- Scikit-Learn Course – Machine Learning in Python Tutorial by FreeCodeCamp.
These are just a few examples of the many resources available on YouTube for learning Scikit-Learn. Depending on your level of expertise and specific interests, you may find some videos more helpful than others.
Reference Documentation and Forums
The official scikit-learn website (https://scikit-learn.org) is a comprehensive resource for learning about the library. The site includes tutorials, examples, and a detailed API reference.
- Scikit-Learn Documentation: The official documentation for Scikit-Learn is a comprehensive resource that provides detailed explanations of Scikit-Learn’s modules, classes, and methods, as well as examples and tutorials. [Link: https://scikit-learn.org/stable/documentation.html]
- Scikit-Learn API Reference: The API reference is a list of Scikit-Learn’s classes and methods, with detailed explanations of their parameters and usage. It’s a useful resource for quickly looking up specific classes or methods. [Link: https://scikit-learn.org/stable/modules/classes.html]
- Scikit-Learn GitHub Issues: Scikit-Learn’s GitHub repository is a great place to report issues or bugs with the library. You can also search existing issues to see if your problem has already been addressed. [Link: https://github.com/scikit-learn/scikit-learn/issues]
- Scikit-Learn User Forum: Scikit-Learn’s user forum is a community-driven platform where users can ask and answer questions about Scikit-Learn. It’s a helpful resource for getting help with specific problems, as well as for learning more about Scikit-Learn’s advanced features. [Link: https://scikit-learn.discourse.group/]
- Stack Overflow: Stack Overflow is a popular Q&A forum for programming questions, and Scikit-Learn questions are no exception. You can search for existing Scikit-Learn questions or ask your own, and the community will provide answers and suggestions. [Link: https://stackoverflow.com/questions/tagged/scikit-learn]
Reference Technical Books
Here are some books that can help you learn scikit-learn:
- “Python Machine Learning” by Sebastian Raschka, published by Packt Publishing (2015), ISBN-13: 978-1783555130. This book provides a comprehensive introduction to machine learning using Python, with a focus on Scikit-Learn. It covers topics such as data preprocessing, model selection, and evaluation, and provides plenty of hands-on examples.
- “Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow” by Aurélien Géron, published by O’Reilly Media (2019), ISBN-13: 978-1492032649. This book is a practical guide to machine learning using Scikit-Learn, Keras, and TensorFlow. It covers topics such as data preprocessing, feature engineering, and deep learning, and provides plenty of code examples.
- “Mastering Machine Learning with scikit-learn” by Gavin Hackeling, published by Packt Publishing (2014), ISBN-13: 978-1783988365. This book is a comprehensive guide to machine learning with Scikit-Learn. It covers topics such as data preprocessing, model selection, and evaluation, and provides plenty of code examples and case studies.
- “Applied Machine Learning” by Kelleher, John D. and Tierney, Brian, published by Springer (2018), ISBN-13: 978-3030040321. This book provides a practical guide to machine learning using Python and Scikit-Learn. It covers topics such as feature engineering, model selection, and evaluation, and provides plenty of hands-on examples.
- “Introduction to Machine Learning with Python: A Guide for Data Scientists” by Andreas C. Müller and Sarah Guido, published by O’Reilly Media (2016), ISBN-13: 978-1449369415.
These books provide a range of approaches to learning Scikit-Learn, from beginner-friendly introductions to in-depth technical guides. Depending on your level of expertise and specific interests, you may find some books more helpful than others.
Cheat Sheet
The scikit-learn cheat sheet from DataCamp is a helpful resource for users looking to quickly and efficiently use the scikit-learn library. This cheat sheet provides a concise overview of the most commonly used functions and methods in scikit-learn, including information on regression, classification, clustering, and dimensionality reduction algorithms. It covers key topics such as feature extraction, model selection and evaluation, and ensemble methods.
Conclusion
In conclusion, Scikit-Learn is a powerful and widely-used Python library for machine learning, providing a range of algorithms and tools for data preprocessing, model selection, and evaluation. Its easy-to-use API and extensive documentation make it accessible to both beginners and experts in the field of machine learning, and its active user community and developer support ensure that it continues to evolve and improve over time. Whether you’re building a predictive model for a business application, working on a research project, or just learning about machine learning, Scikit-Learn is a valuable resource to have in your toolkit.


{kind=link}